
- > 製品一覧
- > AI創薬の学習用化合物データベースGOSTAR


-
-
ベンダー情報
-
ベンダー情報
-
イベント情報Webセミナー「Excelra社 低分子医薬化合物データベースGOSTAR(新UI)」
主催:伊藤忠テクノソリューションズ株式会社 参加費用:無料 -
ベンダー情報
-
最新情報
-
ベンダー情報
-
ベンダー情報
-
ベンダー情報
-
ベンダー情報
-
ベンダー情報
-
最新情報
-
ベンダー情報
-
ベンダー情報
-
ベンダー情報
-
ベンダー情報
-
ベンダー情報
-
ベンダー情報
-
イベント情報Webセミナー「リニューアルされたバイオマーカーデータベースGOBIOM+のご紹介」
主催:伊藤忠テクノソリューションズ株式会社 参加費用:無料 -
イベント情報Webセミナー「AI創薬のための機械学習用データセットのご紹介~低分子医薬系化合物データベース GOSTAR(Excelra社)~」
主催:伊藤忠テクノソリューションズ株式会社 参加費用:無料 -
ベンダー情報
-
ベンダー情報
-

製品概要
低分子医薬系化合物データベースGOSTARは、Excelra社の優秀な科学者がマニュアルキュレーションで選抜した、800万化合物及び特許論文から2,800万件のSAR情報を収載したコンテンツソリューションです。
Webベースのシステムで、インターネットに接続できる環境ならどこからでもアクセス可能です。
GOSTARは、主にメディシナルケミストによるSAR(構造活性相関)解析、AIやML(機械学習)モデルによる創薬の学習用データセットとして利用が拡がっており、世界大手製薬始めアカデミック、バイオテック企業などでデファクトスタンダートで使用されています。

創薬研究開発の探索、トランスレーショナルリサーチ、臨床まで幅広くご利用いただけます!
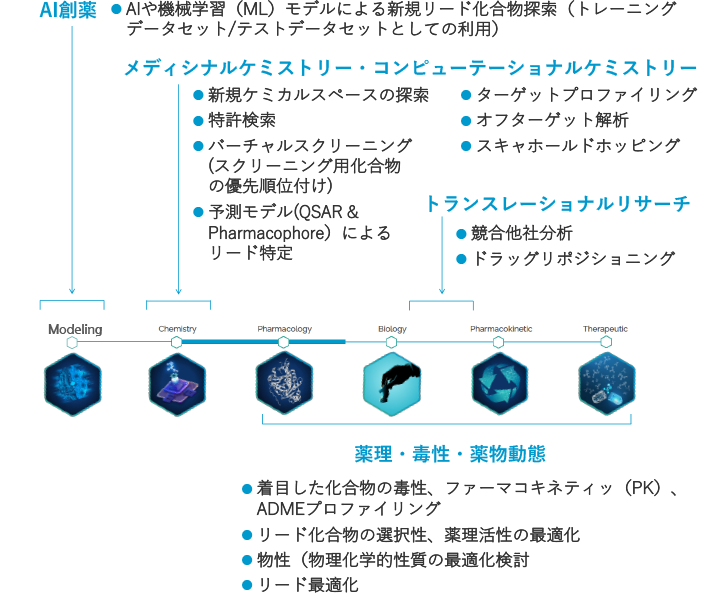
製品の特長
網羅的なデータ
- 世界最大規模のデータ量
- データベース全体を通じて用語が統制
- 正規化・標準化されたデータフィールド
- セマンティック技術を用いた網羅的なデータ紐付け
使いやすく柔軟なシステム
- Webブラウザーからオンラインでアクセス可能
- ユーザーが自社で保有するデータの登録が可能
- SDファイル・RDファイル・Excel・XML・CSV形式でデータ出力
豊富な機能
- 50データフィールド以上もの豊富な検索オプション
- 標準機能で、化学構造ドローイングツールと解析ツールを実装

検索からスタート!
化合物に関する情報(化合物名・CAS番号・SMILES/SMARTS形式の構造情報)や、活性情報(タンパク質名や活性値)、文献目録、化合物のステータス(探索段階・開発中・市販医薬品)など詳細な情報を条件設定して、検索できます。
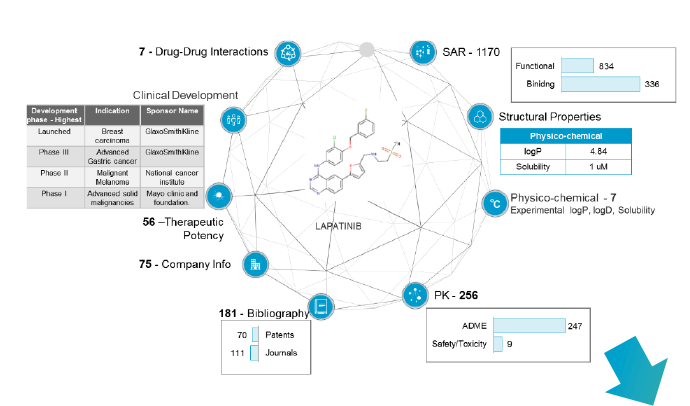
データを用いた解析で新規知見の抽出化合物を中心としたデータの参照
上市医薬品の基礎研究データに基づき、
自社開発化合物のヒントを得る
様々な切り口によるデータを閲覧
収録コンテンツ
膨大なデータソースをセマンティック技術で紐づけ、正規化・標準化された合理的なデータベース
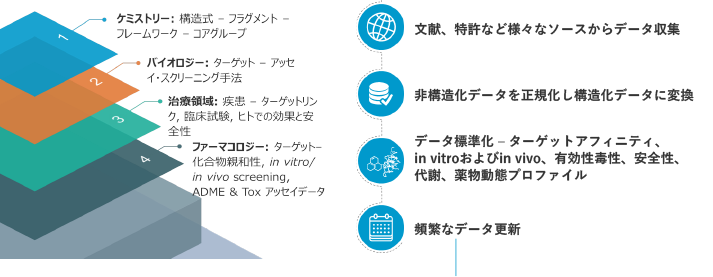
世界最大級のデータ量 ※2019年7月現在
化合物 :約8,000,000件(前臨床、臨床、承認薬含む)
論文 :約342,392件
特許 :約2,200,000件
SAR情報:約28,000,000件
毎月データを更新
平均の更新件数/回
化合物 :約12,000件
アッセイ :約2,000件
SAR情報 :約58,000件
ケミカルデータ
SMILES、毒性構造/代謝物、InChi、Lipinskiデータ、CAS番号、化合物名とシノニム、骨格、フレームワーク、環状、core group、天然物
臨床試験データ
前臨床 :215,000件
臨床 :20,000件
上市医薬品 :5,000件
バイオロジカルデータ
- シノニムを含むバインディング & アッセイタンパク質、セルライン、ソース、正式名称、gene/entrez ID、PDBID
- ADME:種別、代謝酵素、species、Mode of conversion、CYP酵素
- 毒性:一般、代謝物データを伴う臓器特異的な毒性
- 標準オントロジー:治療領域(ICD-10)、副作用情報 (MedDRA)、タンパク質 (NCB!)
特許・文献
公開済み特許情報(US・WO・DE・EP・GB・ FR・JP)論文・ジャーナル、著者、PUBMED ID、DOI、会社名、M&A(合併&買収)データ
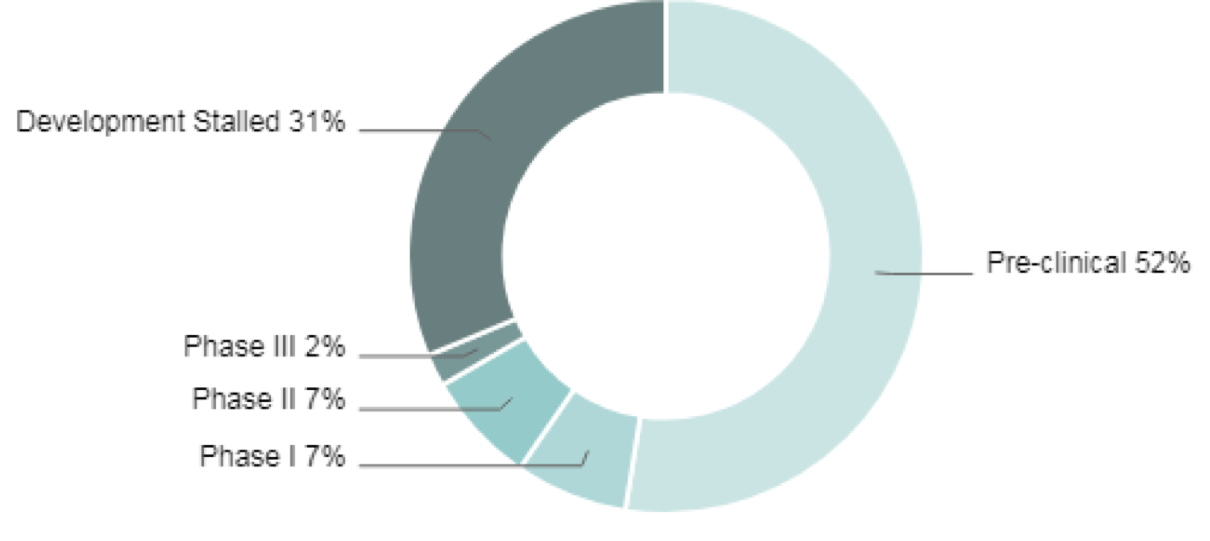

ユーザー事例
事例1: 大手米国製薬企業 機械学習モデルによる活性リード化合物の予測
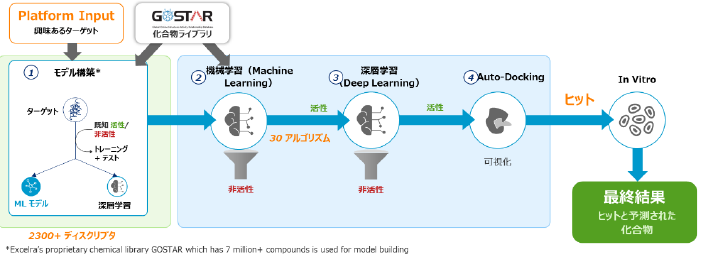
GOSTAR化合物ライブラリ 700万化合物を(当時最大件数)トレーニング、テストデータセットとしてモデル構築に利用した。
製薬企業とのコラボレーションにより、ユーザーが興味あるターゲット情報とGOSTARをインプットデータとして、機械学習と深層学習に基づくモデルを構築。トレーニングとテストを繰り返し、ターゲットに対する活性/非活性の予測精度を高め、活性の見込みがあるリード化合物の予測に成功した。
事例2: Novartis
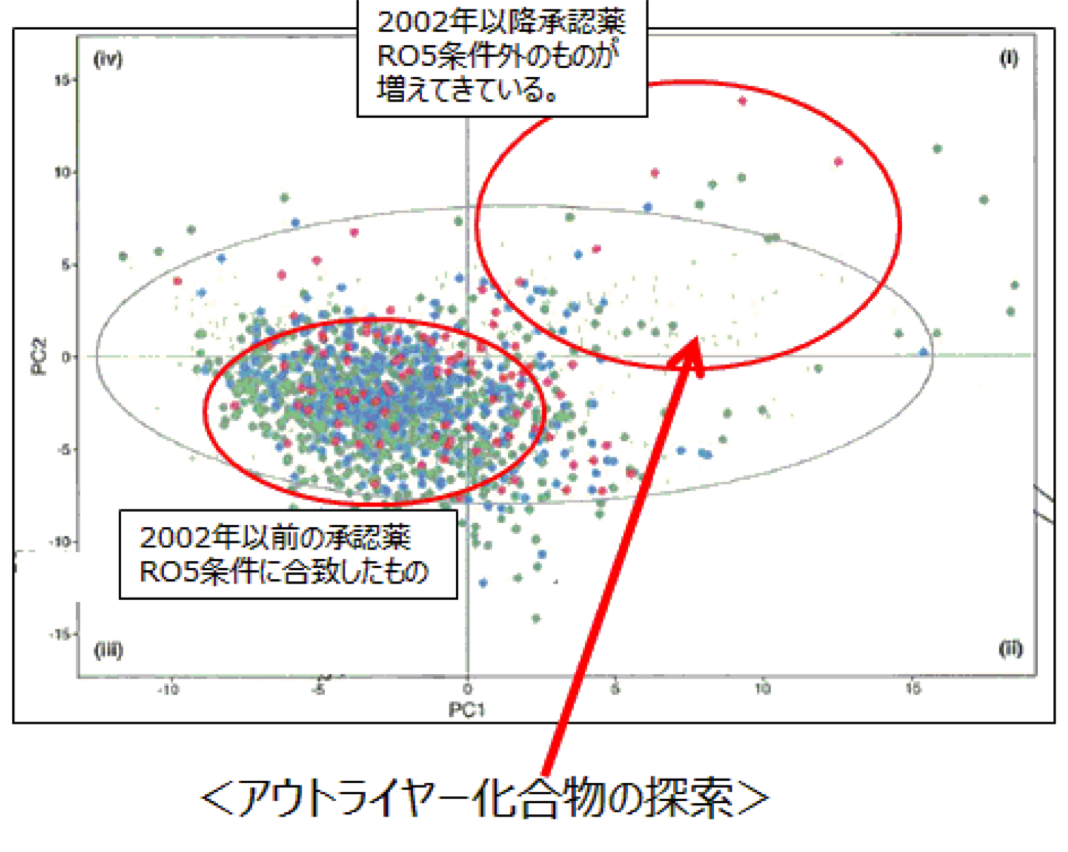
生理活性化合物12,000個、最近医薬品、古い医薬品の性質を比較した。
薬品になる物性はある領域に集中している一方で、2002年以降に承認されている医薬品は伝統的なドラッグスペースから逸脱している。
この新奇な領域では、古典的な医薬品の知識による半経験的ルールは必ずしも適用できない。別の新しいアプローチが求められることが分かった。
解析用のデータセット
MCD: 生理活性化合物のassay情報をjournalからキュレーションしたDB
Drug Discov Today. 2011 Nov;16(21-22):976-84.
事例3: AstraZeneca
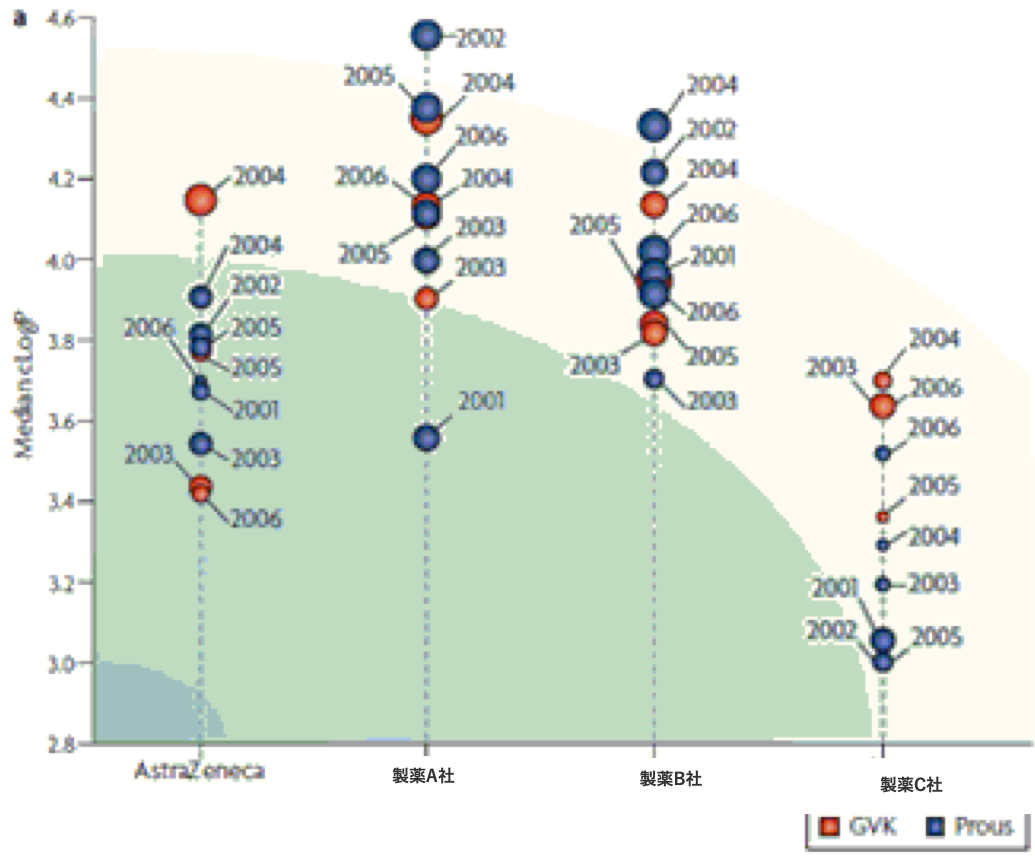
- 経口投与薬と治験薬のLipinskiパラメータの傾向を製薬企業毎にトレンド解析した。
解析用のデータセット
Kinase, GPCR, IC, Transporter, NHR, Phosphatase - 製薬企業ごとの開発候補化合物のLipinskiパラメータを比較。
(例:製薬企業間での比較、ターゲットタンパク間での比較、マッチドペア解析)
解析用のデータセット
特許をデータソースとする生理活性
化合物のアッセイデータ (all targets)
Nat Rev Drug Discov. 2007 Nov;6(11):881-90.
Nat Rev Drug Discov. 2011 Oct 30;10(10):749-65.
