
- > 製品一覧
- > Tetra Data Platform(TDP)
-
TetraScience社の実験データ統合基盤
Tetra Data Platform(TDP)
解析の民主化 / 高度解析の実現
近年、ライフサイエンス分野では、多種多様な機器を利用し研究が進められ、出力されるデータが機器ごとに接続方式や拡張子、フォーマットが異なっている場合が多く、研究者は実験データの取得、加工、解析を手作業で行っているのが現状です。
このような研究現場での課題を解決すべく、TetraScience社の提供するTetra Data Platform(TDP)は、機器ごとに出力される実験データを自動集約し、汎用的なデータフォーマットに変換・統合し、これらのデータを高度解析の実現に向け強力に支援するAWSネイティブのデータプラットフォームです。
研究現場での課題
研究データを活用した高度解析を阻む研究現場での実情
研究過程で利用するデータソースは様々で、拡張子やフォーマットも多種多様です。研究者がこれらのデータを活用し高度解析を実現するためには、自らマニュアルで各種データソースを取得・加工・標準化作業をおこない、解析ツールや電子実験ノートなどにデータを渡す必要があります。これには膨大な時間が必要で、また人為ミスが発生するため、信頼性の観点からも問題です。更に、リアルタイム性に欠けます。このような理由から実際には研究データを活用した高度解析が行われていないのが実情です。
データ活用における課題
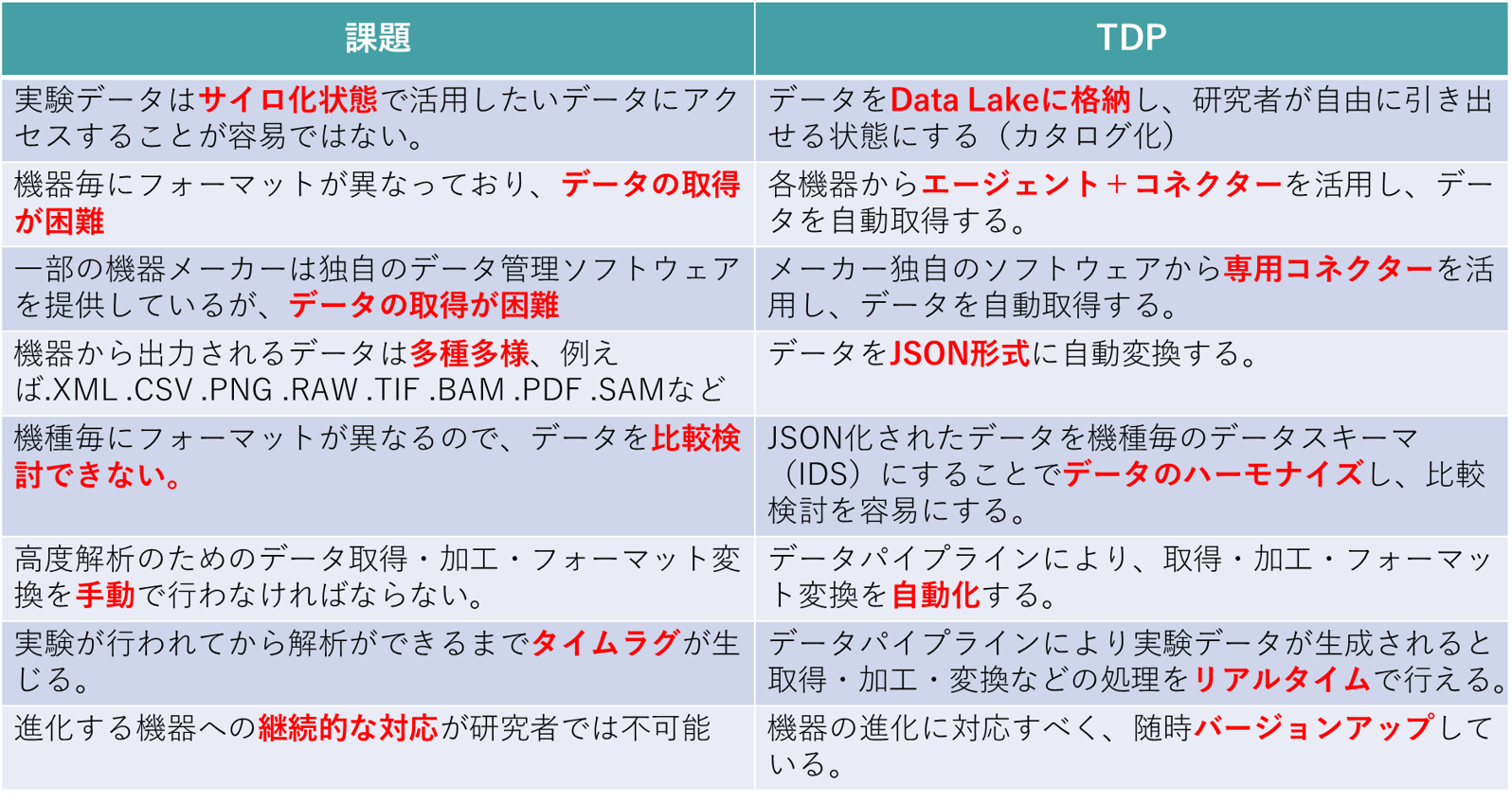
データ活用における解決すべき課題として下記が挙げられます。
- 課題①
- 実験データはサイロ化状態で活用したいデータにアクセスすることが容易ではない
- 課題②
- 機器毎にフォーマットが異なっており、データの取得が困難
- 課題③
- 一部の機器メーカーは独自のデータ管理ソフトウェアを提供しているが、データの取得が困難
- 課題④
- 機器から出力されるデータは多種多様
例えばXML .CSV .PNG .RAW .TIF .BAM .PDF .SAMなど - 課題⑤
- 機種毎にフォーマットが異なるので、データを比較検討できない
- 課題⑥
- 高度解析のためのデータ取得・加工・フォーマット変換を手動で行わなければならない
- 課題⑦
- 実験が行われてから解析ができるまでタイムラグが生じる
- 課題⑧
- 進化する機器への継続的な対応が研究者では不可能
TetraScienceによる課題解決フロー
実験から高度解析までリアルタイムに実施
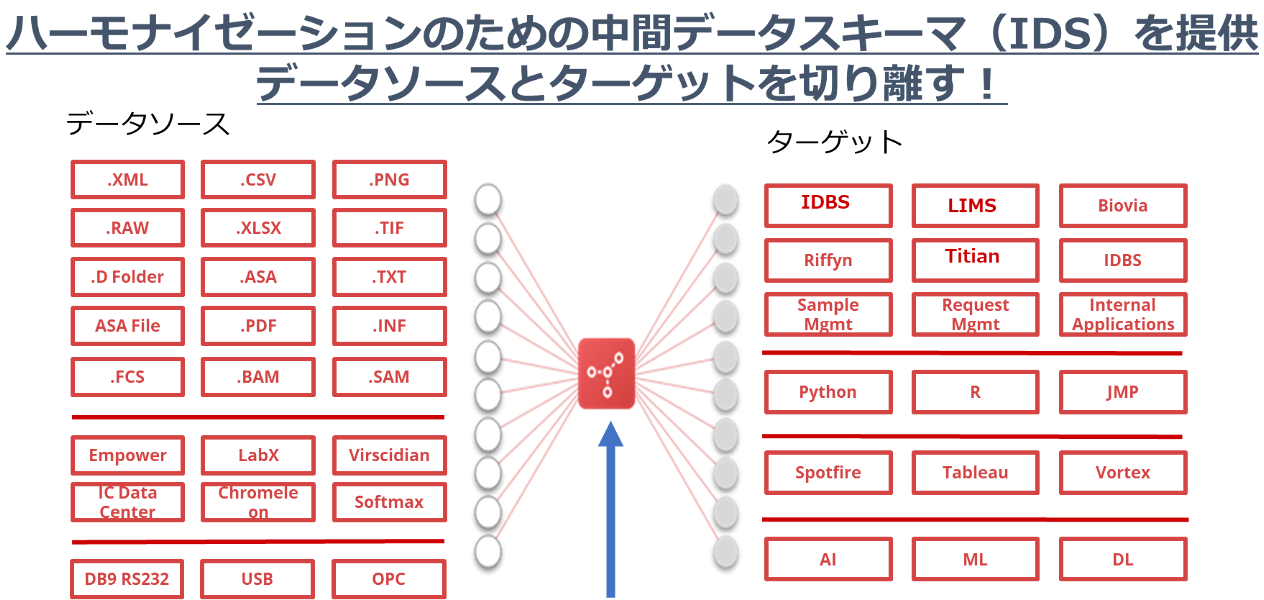
TetraScience社の提供するTetra Data Platform(TDP)は機器ごとに異なるフォーマットやDMSに対応するため、様々な機器に対応するコネクターが用意されています。実験が行われデータが生成されると、コネクターが自動でデータを取得します。取得されたデータはJSON形式に変換され中間データスキーマに格納されることで、データのハーモナイズを実現します。更に、各種処理を行うデータパイプラインを用意しており、データの品質チェック、加工、フォーマット変換、データ統合など、様々なシーンでデータを活用することを強力に支援します。
Tetra Data Platform(TDP)全体像
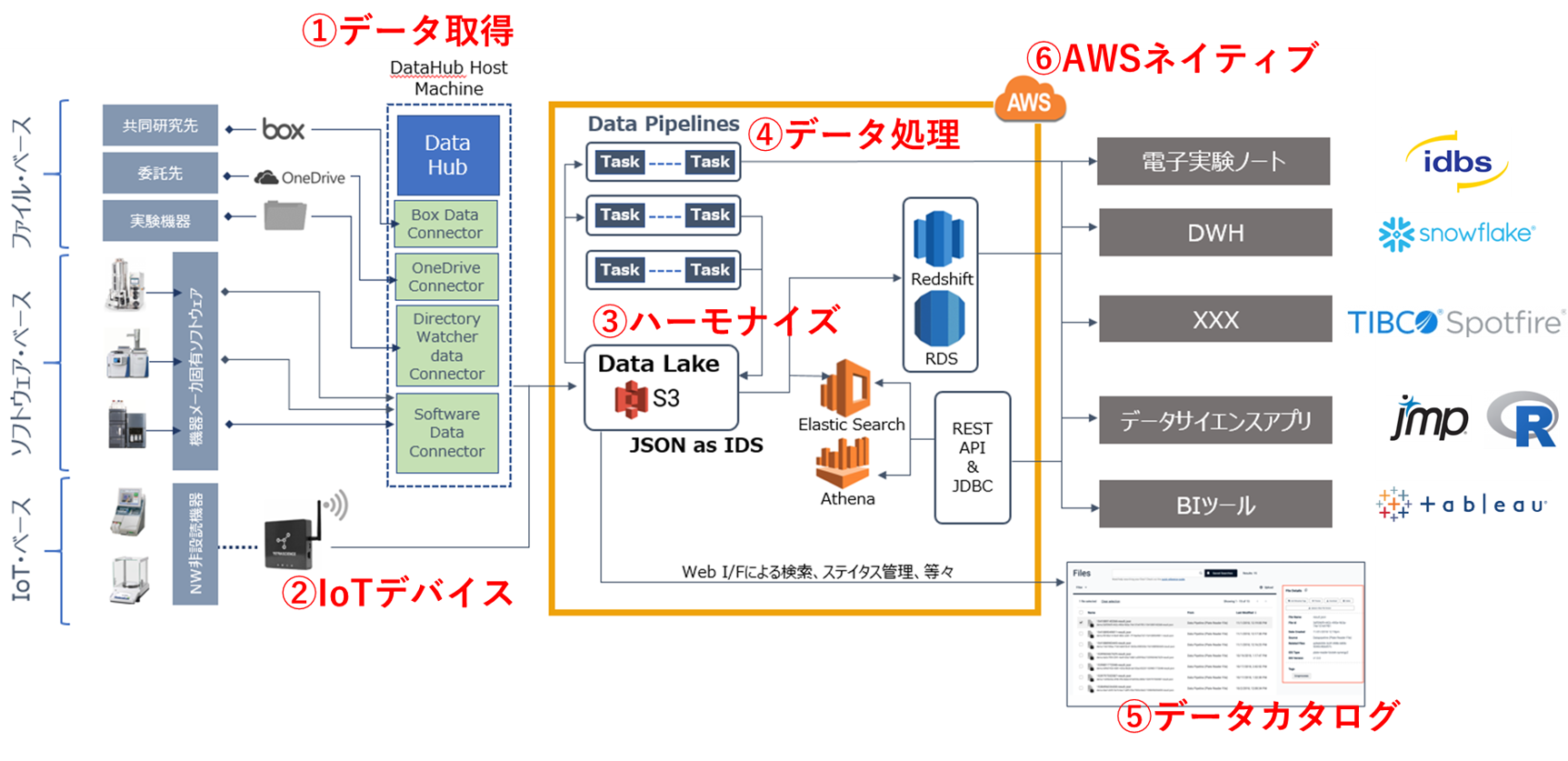
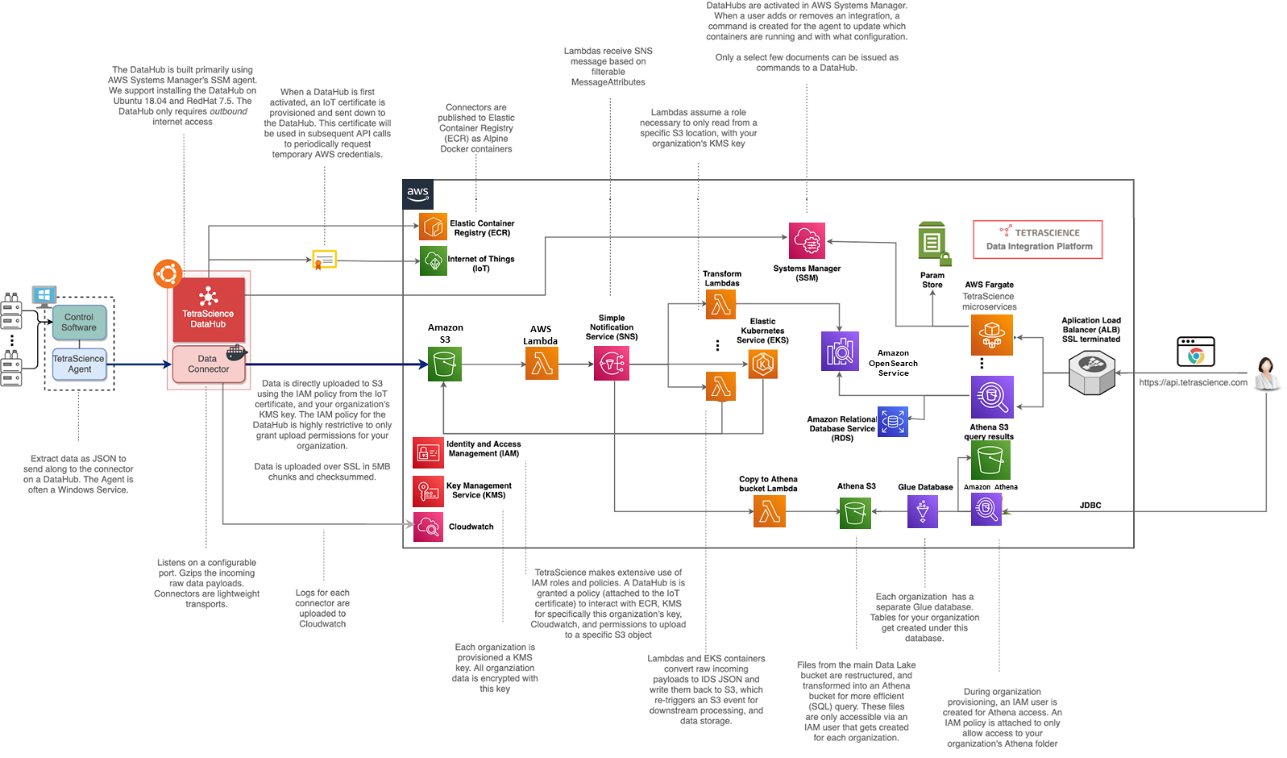
① データの自動取得
DataHub Host Machineが、データの収集のため各File-Log Agentやコネクターを使ってデータを自動収集します。
尚、対応している機器・DMSは、200種類以上におよび、適時追加されるとともに、お客様のご要望により開発することも可能です。
大別して以下の3つの方法でデータを取得します。
1.機器メーカーが提供しているDMSからのデータ取得
Empower、UNICORN、LabXなど各ソフトウェアにネイティブなTetraScienceのSoftware Agentが、実験データを自動収集します。
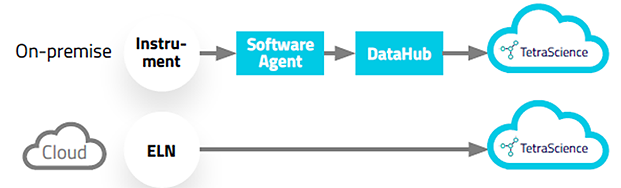
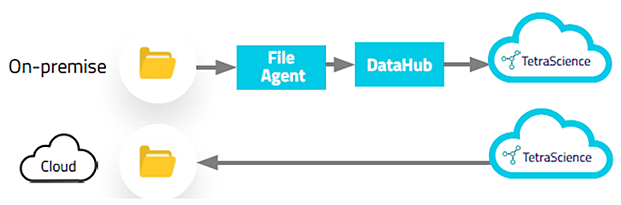
2.ファイルシステムからのデータ取得
File-Log Agentは、実験機器から生成されるデータの出力先フォルダや任意のフォルダ内のアップデートされたファイルを検知し取得します。
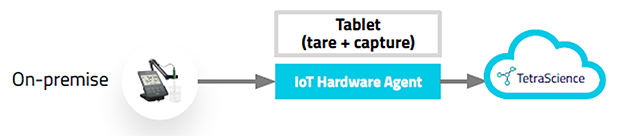
3.ネットワーク非接続の機器
TetraScienceのIoT Agent(Wifi搭載のデバイス)が機器からデータを取得します。
対応機器・DMS一覧(随時更新)
② データハーモナイズ
データをJSON形式に自動変換し、JSON化されたデータを機種別毎の中間データスキーマ(IDS)することでデータのハーモナイズを実現します。
![]() 画像拡大
画像拡大
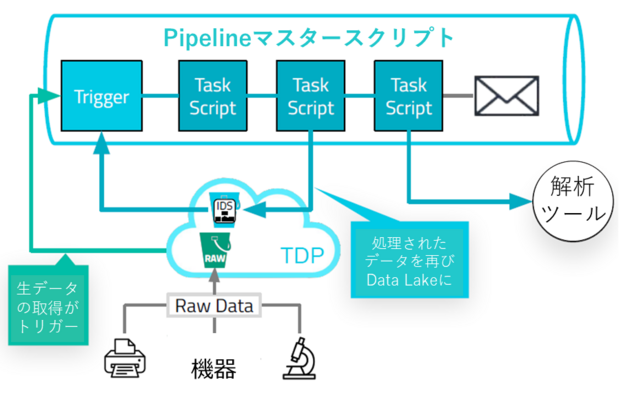
③ データ処理(Data Pipeline)
Data Pipelineとは、AWS S3上で管理されているデータに対し様々な処理を自動化するETL機能です。
S3にデータが転送されるとAWSのSNSによってTriggerが働き、指定されたPipelineが自動的に処理を実行します。 このData Pipelineは様々な用途で用いられます。
- データの品質チェック(欠損やプロトコール逸脱など)
- 解析に必要な異なった機器からのデータの収集やマージ
- 高度解析のためのデータ変換
(解析ツール、ML、ELNなどでの活用) - DWHなど外部システムへのデータ受け渡し
- サンプル管理システムからのデータを受け取り、Data Lake内の情報の強化
- ロボティクス・コントロール
- 定型レポートの自動作成
④ データカタログ
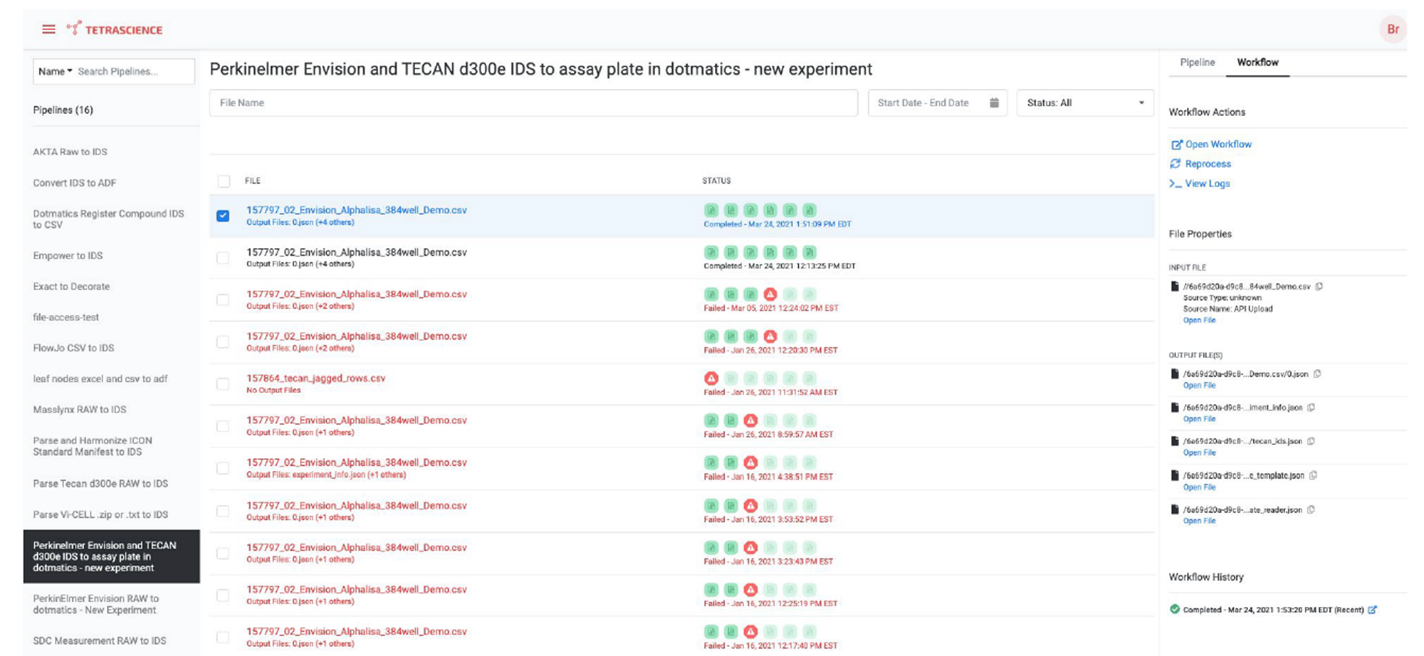
取得したデータをWeb I/Fから直接検索することが可能です。viewのカスタマイズも容易で、様々なフィルターを組み合わせることで情報を的確に確認することが出来ます。
また、Pipelineのモニタリングもでき、データ処理の進捗をタイムリーに把握することも可能です。
導入のご相談
Tetra Data Platform(TDP)は、ライフサイエンスの分野において実験機器ごとに異なる拡張子やフォーマットで出力される実験データを一元的に集約し、汎用的なデータフォーマットに変換して統合するクラウド型のデータプラットフォームです。データを統合することで、解析や分析、レポートを含めた研究の様々な場面でのデータの活用が期待できます。
エンタープライズ第3本部では、化学/材料、ライフサイエンス、CPG、食品などの研究開発に取り組まれるお客様に、各種業務を支援するICTソリューションを提供しています。イノベイティブな研究開発・製造・販売、そして品質と安全性の向上に貢献していきます。
先ずは、下記のお問合せフォームからお気軽にご連絡ください。
