[読了時間:5分]
伊藤忠テクノソリューションズ株式会社(以下、CTC)は、2019年6月4日(火)、東京都品川区のInnovation Space DEJIMAにて、AIによるテキスト解析エンジン「Quid」のイベントを開催しました。同イベントは、お仕事帰りにサクッと気軽に立ち寄れるショートセミナーにしたく18:30に開会しました。60名を越えるお客様にご参加いただき、盛況の内に終了しました。今回はCTCのエンジニア 青木 桜より、テキスト解析の需要が高まる背景やQuidの製品説明、競合分析の事例紹介を行いました。
これから3回にわたり、発表のサマリーをお届けします!
世界の情報の80%はテキストデータが占めるという事実
皆様は80%という数字を聞いて、「想像以上にテキストがたくさん占めているなぁ。」と思われたのではないでしょうか?
テキストデータは、文書やEメール、ニュース、ブログ、ツィート、カスタマーレビュー、電話の会話記録、サポートの問い合わせログなど身近に溢れています。
これらのテキストデータは、果たして活用されているのでしょうか?
データを活用するといって思い浮かべるのは、売上金額や人口動態などの数値をExcelや統計ソフトを使って解析することです。数値データは表などのフォーマットにまとまっている(構造化)ことが多いので、すぐにグラフを描画したり平均値や標準偏差などの値を求めたりすることができます。
一方でテキストデータは、数値とは異なり構造化されていなく(非構造化データ)、解析が難しいと考えられています。そのため、これらのテキストデータは活用されないまま、組織内に眠っていることが多いのです。
しかしテキストデータを読み解くことで、テキストの裏に隠された様々な知見を得ることができます。文書のコンセプトや世間を賑わせている話題(流行)の抽出、膨大な情報から事実の特定、(顧客などの)感情分析、情報の相関性分析などが挙げられます。具体例を挙げると、カスタマーレビューに投稿された情報を分析することで、お客様がサービスに満足したかどうか、また満足度が低い原因には何が多いか特定することで、サービスの品質向上のヒントになります。
それではテキストデータの解析は、どうしたら実現するでしょうか?
AIを用いたテキスト解析エンジンQuid
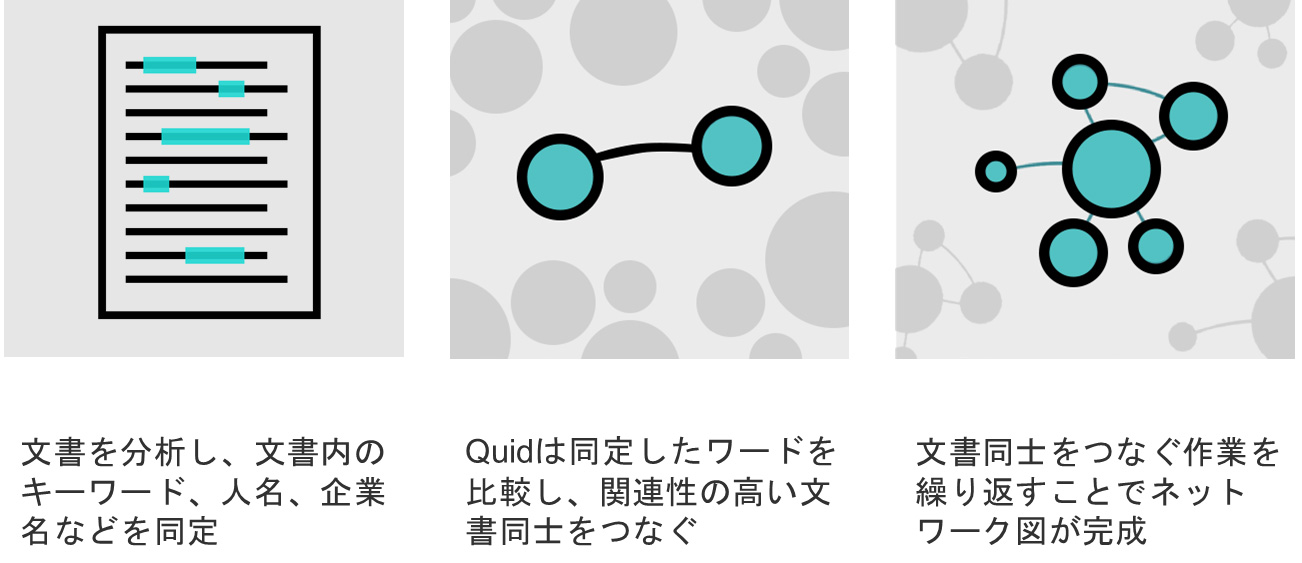
テキストデータは解析しにくいという課題を解決するソリューションとして、AIを用いたテキスト解析エンジン「Quid」が開発されました。Quidは、自然言語処理によりテキスト情報を読み解き、関連性の高いドキュメント同士をグループ化します。
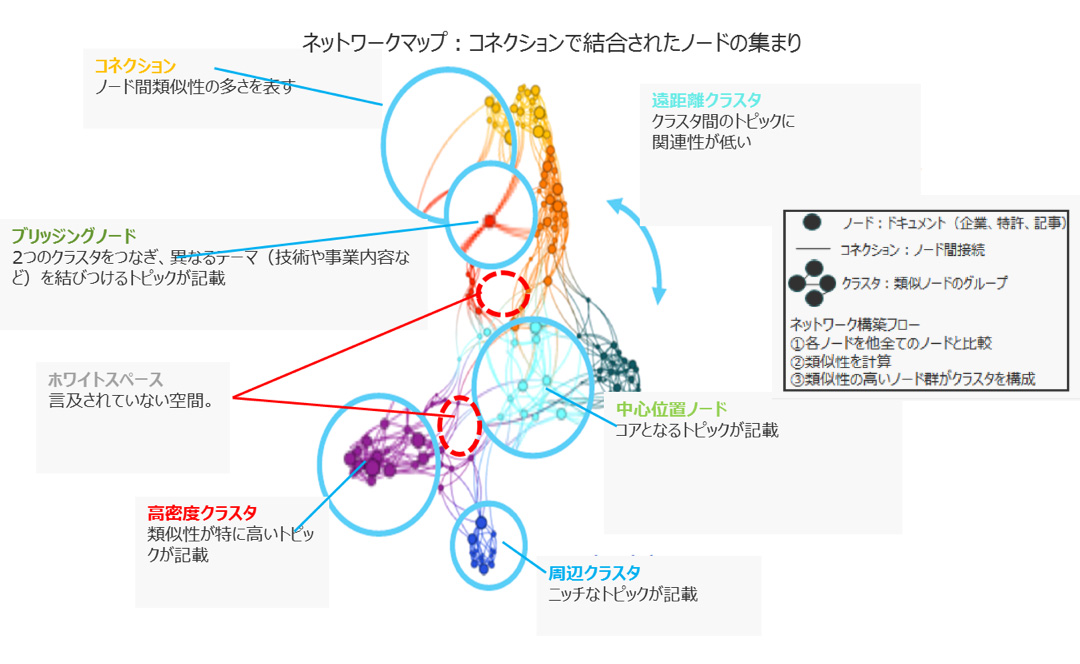
そしてグループ化した情報は、独特のネットワークマップでビジュアル化します。
例として、人工知能のスタートアップにはどのような企業があるかQuidを用いて解析したところ、次のような結果が出ました。
Googleなど検索エンジンで「人工知能 スタートアップ」でサーチすると、約213万件がヒットしました(2019年9月5日現在)。これらを一つずつ人力で解読していくのは、ほぼ不可能です。しかし、Quidの解析では全てのデータを解読し俯瞰したうえで、どの分野のスタートアップが多く存在するのか、また近しい技術を持つスタートアップ同士の相関も分かります。このようにテキストを単にグルーピングするだけでなく、新たな知見を引き出せるようなビジュアライズもまたQuidの特長です。
Quidが解析可能なテキストデータ
一口にテキストデータといっても、その種類は幅広くあります。そのため、Quidが解析可能なデータセットの例をご紹介します。
先ずQuidに標準装備されている統合データセットには、ニュースブログ、180万以上の企業データ、500の管轄権にまつわる特許データがあります。しかしこれだけでは、各企業が独自に保有している情報の解析は行えません。そこで、オンラインフォーラム・掲示板、製品レビュー、ソーシャルメディア、アンケート結果など顧客の声(Voice of Customer)や、求人情報、臨床試験、保有技術などの競合調査情報、コールセンターの記録や従業員アンケートなど内部資料もまた追加でアップロードすることで、解析可能になります。
このようにQuidは世の中に溢れているテキストデータを自然言語処理(NLP)で読み解き、体系的に視覚化、即座にインサイト(知見)へと導くお手伝いをします。
Quidで何ができるか概要をお伝えしましたが、次回はQuidを用いた競合分析の事例についてご紹介します。ぜひご期待ください!
- 記載されている商品名などの固有名詞は、各社の商標または登録商標です。
- 掲載されている情報は、発表日現在の情報です。最新の情報と異なる場合がありますのでご了承ください。
- 部署名、役職名、その他データは、イベント開催当時のものです。